
Bis zum Jahr 2020 werden mehr als 50 Milliarden Geräte Zugriff auf das Internet haben (Huber, D. & Kaiser, T. HMD (2015) Vol. 52 S. 681 ff.). Durch das Internet der Dinge erwarten uns in den kommenden Jahren eine Vielzahl an Innovationen und neuen Geschäftsmodellen, weil nicht nur Computer, Laptops und Smartphones, sondern auch vernetzte Geräte in Autos, Maschinen oder Häusern online sind.
Eine der bedeutendsten Herausforderungen und Chancen besteht künftig deshalb darin, aus den anfallenden Datenmassen einen betriebswirtschaftlichen Nutzen zu generieren, indem z. B. eine fundierte Entscheidungsunterstützung oder verbesserte Kundenservices ermöglicht werden.

Voraussetzung einer erfolgreichen Business-Intelligence-Strategie zur Verarbeitung und Analyse von großen Datenmengen ist deshalb ein Data Warehouse, das auf die bevorstehenden Herausforderungen vorbereitet ist und flexibel auf neue Datenquellen und Anforderungen reagieren kann. In diesem Artikel wird deshalb der Frage nachgegangen, inwiefern sich Data Vault von anderen Modellierungsmethoden unterscheidet und ob es sich dadurch besonders gut für ein agiles Data Warehouse eignet.
Für die Auswertung des Reportings und für die Analyse hat sich in der Praxis eine Trennung der operativen und der strategischen Daten durchgesetzt, indem die operativen Daten zur Konsolidierung, Verdichtung und Analyse in ein Data Warehouse (DWH) kopiert werden. Durch das Extrahieren der Rohdaten (E) können diese in einem zweiten Schritt transformiert werden (T), um in eine gemeinsame Struktur überführt und in ein DWH geladen zu werden (L). Durch diese stetig laufenden ETL-Prozesse soll eine fortführende Befüllung eines DWH garantiert werden, um ein möglichst aktuelles und einheitliches Gesamtbild auswerten zu können. Hierbei spielt die Modellierung der Datenbank eine entscheidende Rolle.
Bei der Modellierung von relationalen Datenbanken beispielsweise versucht man die großen Datenmengen mit einer möglichst redundanzfreien Datenspeicherung in den Griff zu bekommen. Solche Datenbanken sind durch ihre Tabellenschemata jedoch ziemlich starr und daher häufig nicht für ein agiles DWH mit wechselnden Anforderungen wie Strukturerweiterungen geeignet.
Zur Veranschaulichung werden in folgendem Abschnitt die in der Praxis häufig angewendeten Sternschema und Schneeflockenschema aufgegriffen und anschließend anhand eines Beispiels aufgezeigt, welche Auswirkungen einfache Strukturerweiterungen auf das entsprechende Datenmodell haben können:
Das Sternschema
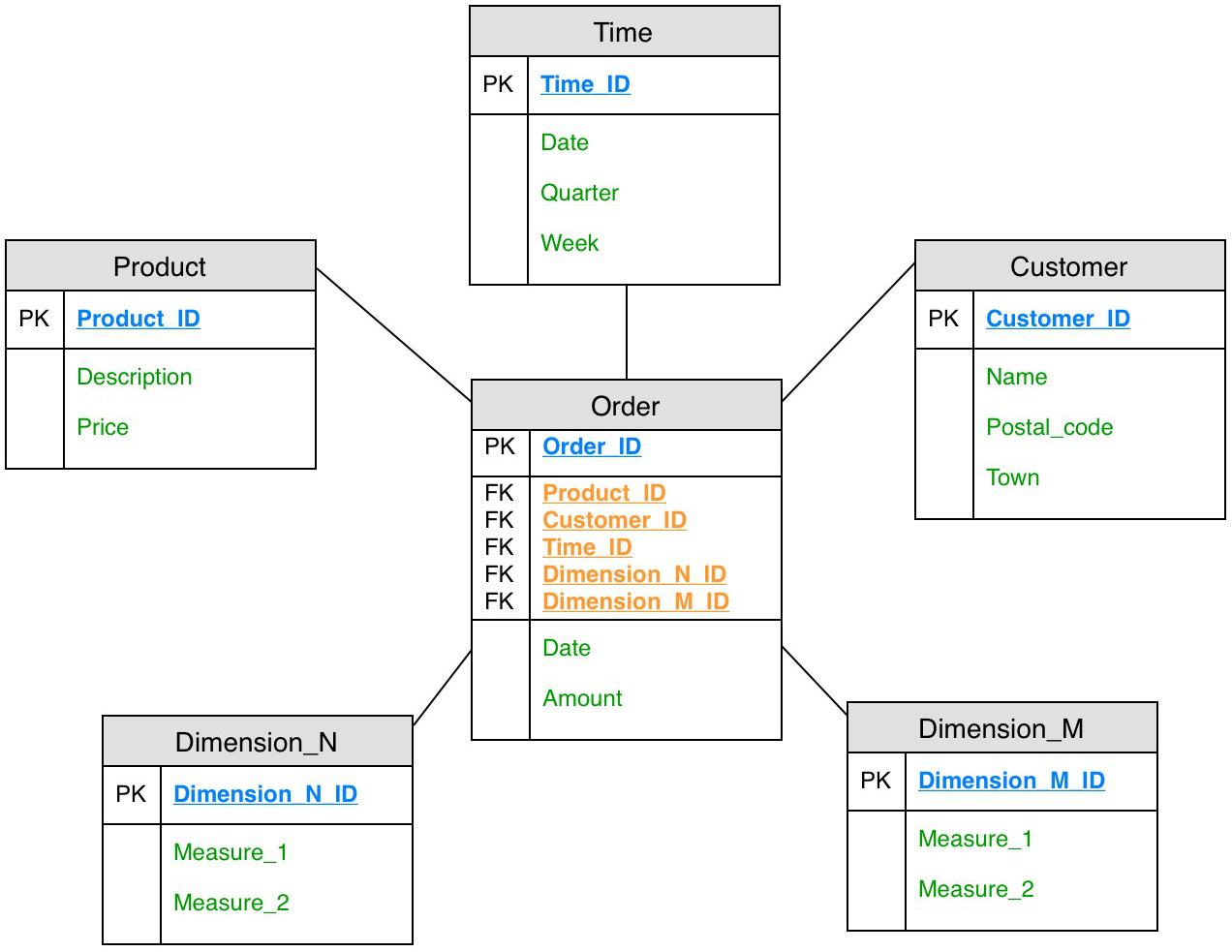
Das Datenmodell des Sternschemas zielt auf optimale Lese-Operationen ab. Eine zentrale Rolle des Sternschemas spielt die sogenannte Faktentabelle, um die sich mehrere Dimensionstabellen anordnen. Die Primärschlüssel der verschiedenen Dimensionstabellen bilden dabei den zusammengesetzten Primärschlüssel der Faktentabelle. Das folgende Datenmodell versinnbildlicht den Namen „Sternschema“, der sich aus der typischen Anordnung der Dimensionstabellen um die zentrale Faktentabelle erschließt.
Der optimierte Lesezugriff des Sternschemas kann allerdings zu Lasten des Speicherbedarfs gehen, da es sich in der Regel um ein denormalisiertes Datenmodell handelt. Die Kombination aus Postleitzahl und Stadt in der Dimensionstabelle Kunde wird hier zum Beispiel für jeden einzelnen Kunden gepflegt, obwohl diese Information für alle Kunden mit der gleichen Postleitzahl redundant ist.
Das Schneeflockenschema

Eine Verbesserung dieser Problematik liefert das Schneeflockenschema, das häufig im traditionellen DWH verwendet wird. Durch eine Normalisierung der Dimensionstabellen fallen weniger redundante Daten an. Für komplexere Abfragen kann es hingegen vorkommen, dass Abfragen über mehrere Tabellen hinweg durch Joins verknüpft werden müssen. Dies geht allerdings zu Lasten der Performance.
Die Verfeinerung einzelner Dimensionstabellen erinnert in der Form an eine Schneeflocke und gibt dem Datenmodell seinen Namen.
Probleme einer Strukturerweiterung im traditionellen DWH

Die Auswirkungen einer möglichen Strukturerweiterung eines traditionellen DWH lässt sich am besten durch ein Beispiel veranschaulichen. Das Datenmodell links bildet einen üblichen Geschäftsvorfall einer Bestellung ab, bei dem sich ein Kunde ein Produkt bestellt.
Eine mögliche Erweiterung des ersten Modells um einen Verkäufer, der an der Abwicklung einer Bestellung beteiligt ist und die neuen 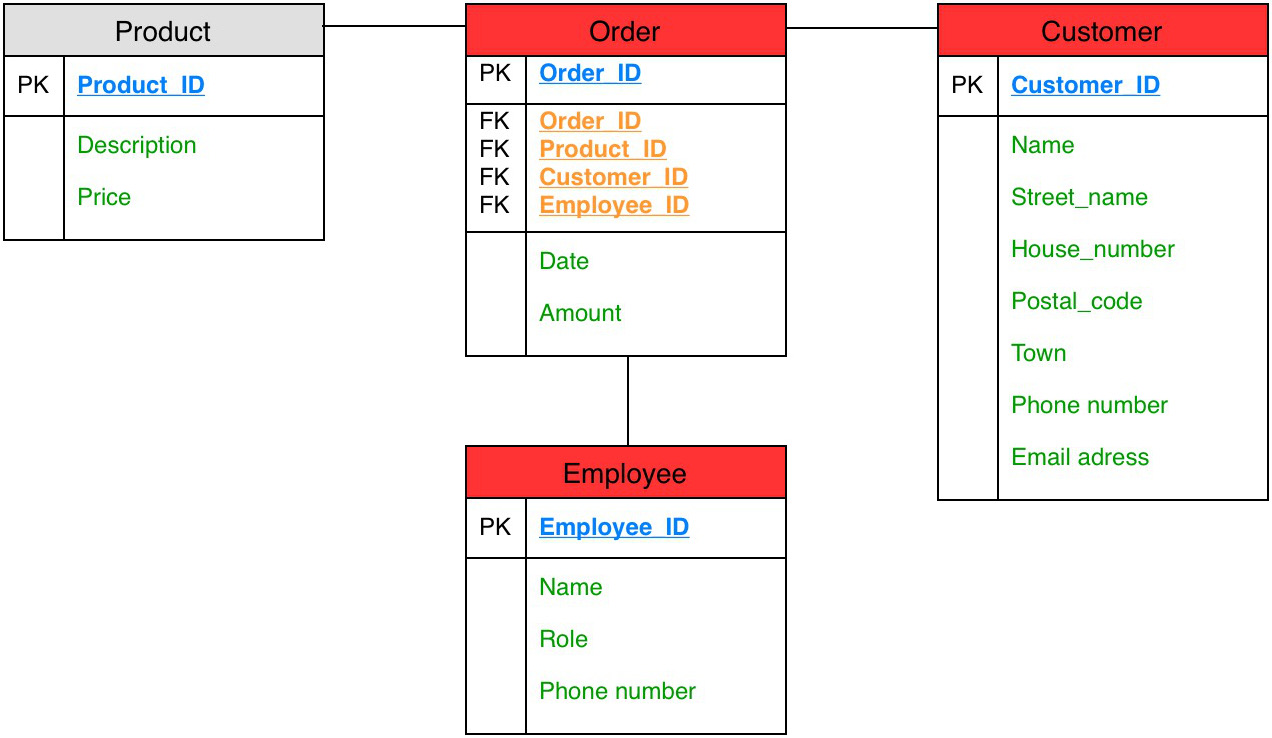 Attribute Telefonnummer und E-Mail-Adresse in der Dimension Kunde wirken sich beinahe auf alle Tabellen aus (rote Tabellen in der Abbildung).
Attribute Telefonnummer und E-Mail-Adresse in der Dimension Kunde wirken sich beinahe auf alle Tabellen aus (rote Tabellen in der Abbildung).
Lediglich die Produkt-Tabelle bleibt von den Updates und den damit verbundenen Arbeiten unberührt. Eine zusätzliche Herausforderung ist zudem die Konsistenz der Daten zu gewährleisten, da es für bereits vorhandene Datensätze einer Bestellung gegebenenfalls keine Informationen über den verantwortlichen Verkäufer gibt oder Telefonnummern und E-Mail-Adressen vorhandener Kunden nicht bekannt sind.
Data Vault
Durch den Druck ein DWH auch schnell und flexibel an neue Anforderungen oder neue Datenquellen anpassen zu können, besteht allerdings häufig das Verlangen nach einer agilen Lösung. Dem Bedürfnis nach effizient erweiterbaren Datenbanken hatte sich Dan Linsted bereits in den 90er Jahren angenommen und die Modellierungstechnik Data Vault ins Leben gerufen. Inzwischen erlebt Data Vault seinen zweiten Frühling und soll vor allem für die agile Entwicklung eines DWH mit häufig zu erwartenden Strukturerweiterungen besser als die traditionellen Lösungen geeignet sein.
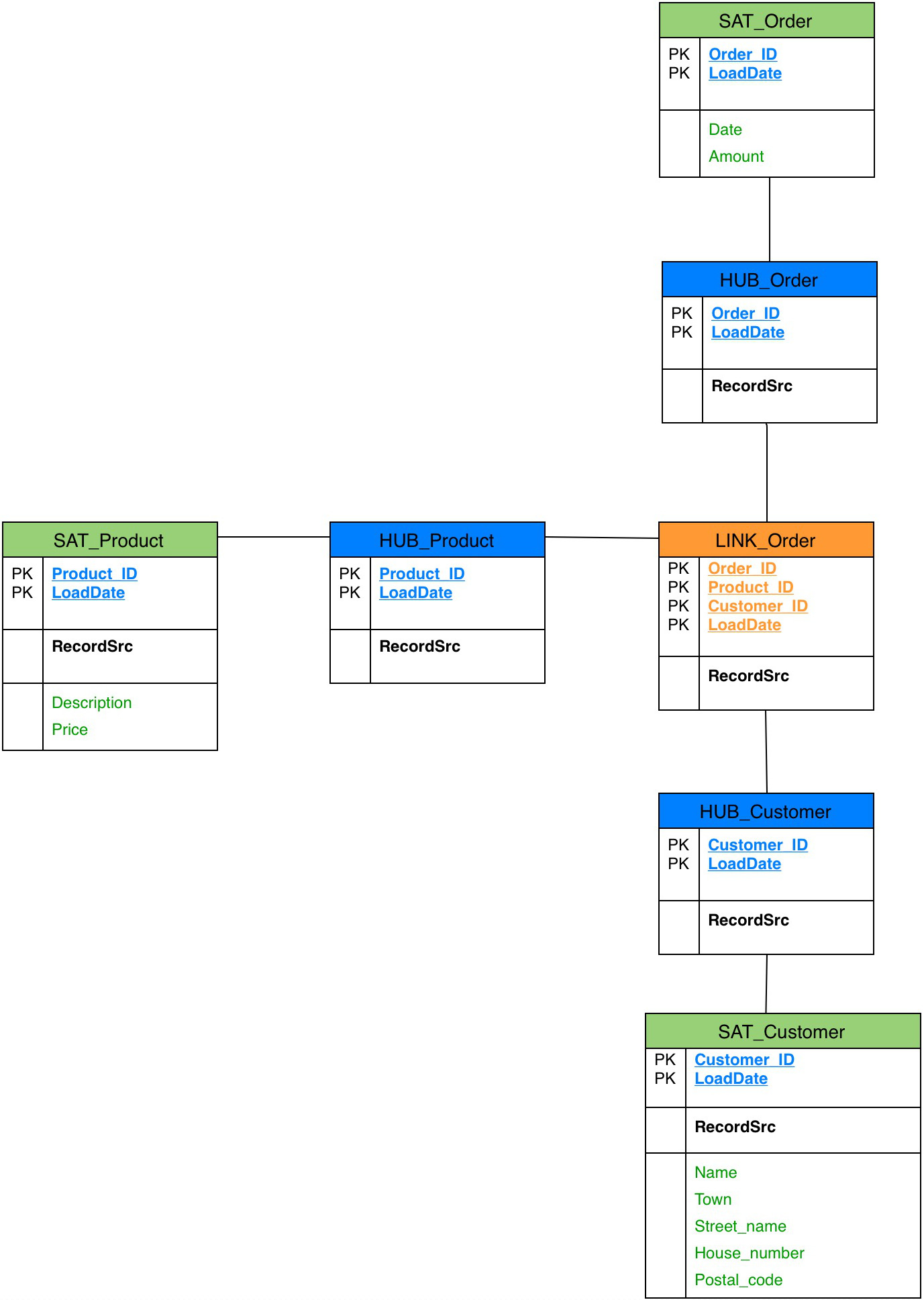
Das Data Vault unterscheidet sich von den vorgestellten Schemata grundlegend. In so genannten Hubs werden die eindeutigen Informationen (Schlüssel) der fachlichen Entität oder ein künstlicher Primärschlüssel gespeichert. Über Link-Tabellen werden die entsprechenden Beziehungen eines Hubs abgebildet. Anders als in der Faktentabelle aus den vorherigen Schemata werden Hubs über diesen Link miteinander verknüpft, indem dort ein zusammengesetzter Primärschlüssel gebildet wird. Ähnlich der Dimensionstabellen werden in den Satelliten die zugehörigen Attribute eines Hubs (Entitäten) oder Links (Beziehungen) gespeichert. Dabei kann ein Hub beliebig viele Satelliten besitzen.
Zusätzlich enthalten alle Tabellen die zusätzlichen Attribute LOAD_DATE und RECORD_SOURCE, um das Quellsystem und den Lade-Zeitpunkt festzuhalten. Durch dieses Historisierungskonzept lassen sich jegliche Änderungen festhalten und auch historische Stände eines DWH wiederherstellen.
Im Data Vault sieht der bereits vorgestellte Geschäftsvorfall einer Bestellung dementsprechend so aus, dass die fachlichen Entitäten Produkt, Kunde und Bestellung in Hubs (blaue Tabellen) über eine Link-Tabelle (orangene Tabellen) miteinander verbunden sind und dort vor allem die Schlüssel-Attribute geführt werden. Beliebig viele Satelliten können darüber hinaus die einzelnen Hubs mit detaillierteren Informationen füllen (grüne Tabellen).
Strukturerweiterung im Data Vault
Bei der geplanten Erweiterung kann bei dem Data Vault Modell das komplette Grundgerüst des Modells bestehen bleiben, da neue Attribute in neuen Satelliten aufgenommen werden können (hier im Satelliten Kunden-Kommunikation) und neue Tabellen über weitere Links mit einem existierenden Hub verlinkt werden können (hier im Link, der den verantwortlichen Verkäufer einer Bestellung zuordnet). 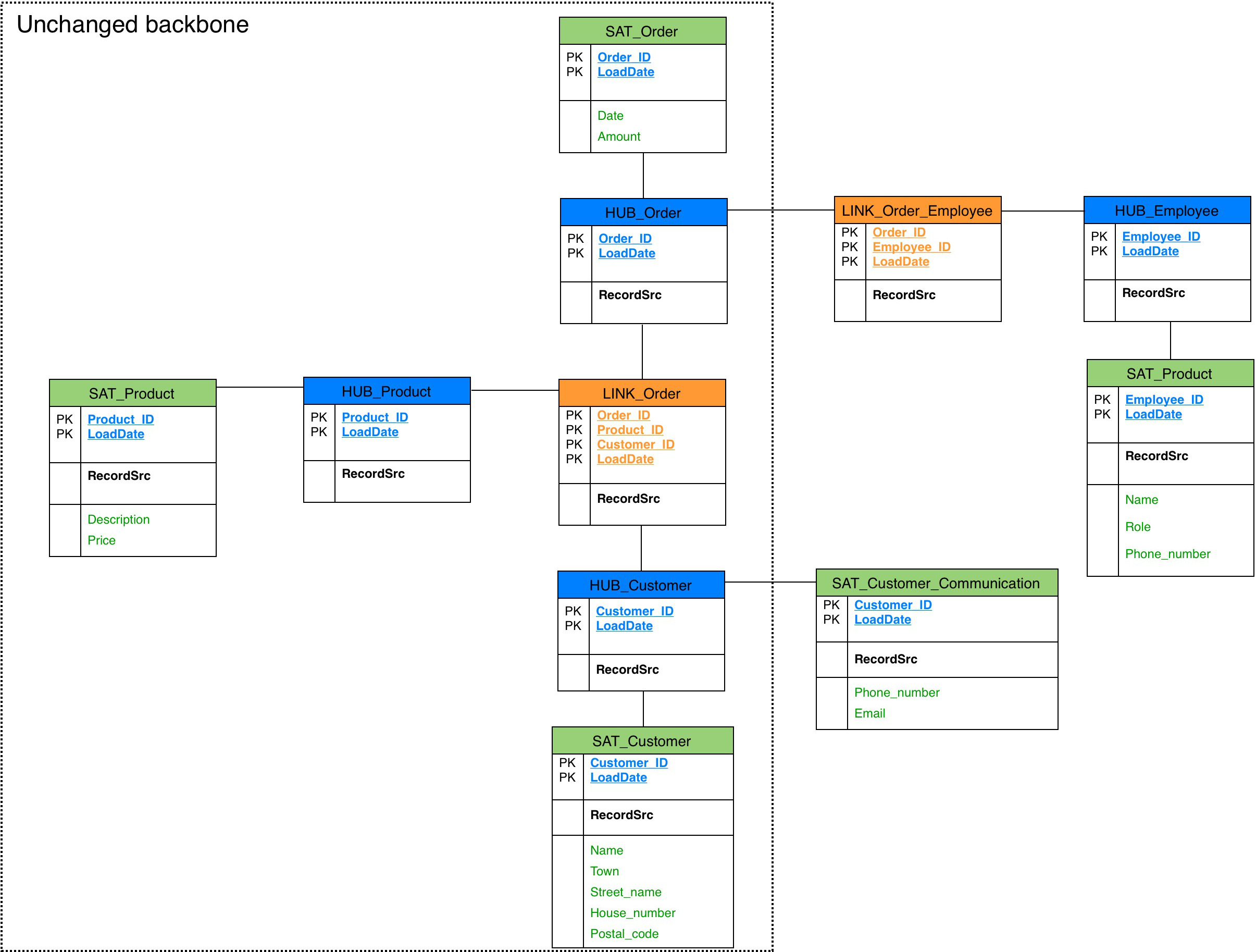 Durch dieses Vorgehen lassen sich sowohl vorhandene Attribute ändern, neue Attribute einpflegen oder neue Konzepte integrieren, ohne das existierende Grundgerüst verändern, updaten oder zerstören zu müssen. Dadurch kann sowohl in der Konzeption, als auch in der Umsetzung viel Aufwand gespart werden.
Durch dieses Vorgehen lassen sich sowohl vorhandene Attribute ändern, neue Attribute einpflegen oder neue Konzepte integrieren, ohne das existierende Grundgerüst verändern, updaten oder zerstören zu müssen. Dadurch kann sowohl in der Konzeption, als auch in der Umsetzung viel Aufwand gespart werden.
Fazit
Mit Data Vault wurde eine Modellierungstechnik, die besonders im agilen Umfeld mit wechselhaften Anforderungen schnelle und flexible Lösungen bereitstellen kann, wiederentdeckt. Durch die strikte Trennung der Hubs, Links und Satelliten bietet das Data Vault die Möglichkeit, viele Quellsysteme einfach zu integrieren, zu erweitern und solche Anpassungen aufgrund des zugrunde liegenden Historisierungskonzepts zu dokumentieren. Zusätzlich handelt es sich durch die klaren Modellierungskonventionen um eine schnelle und vergleichsweise einfache Modellierungstechnik, deren ETL-Prozesse gut parallelisiert werden können. Wie das vorgestellte Beispiel einer Strukturerweiterung zeigt, verbirgt sich der größte Vorteil des Data Vault allerdings in seiner Flexibilität.
Trotzdem sollte natürlich weiterhin Vorsicht geboten sein: im Data Vault erkauft man sich die Flexibilität durchaus zu Lasten komplexerer Abfragen, da vermehrt Joins über mehrere Tabellen nötig sein können.
Bei der Wahl der richtigen Modellierungstechnik für eine agile Datenhaltung sollte man sich aber durchaus intensiver mit Data Vault auseinandersetzen.

